I want to improve our stream loading times and take another chance with the Evil Query. Since query optimizers choose the most efficient execution plan for the query at hand depending on the current data set, I need a database filled with life, that is, with data that is typical for a normal pod.
To that end, I took a first step and mapped out an ER model for the entities involved in the creation of our streams.
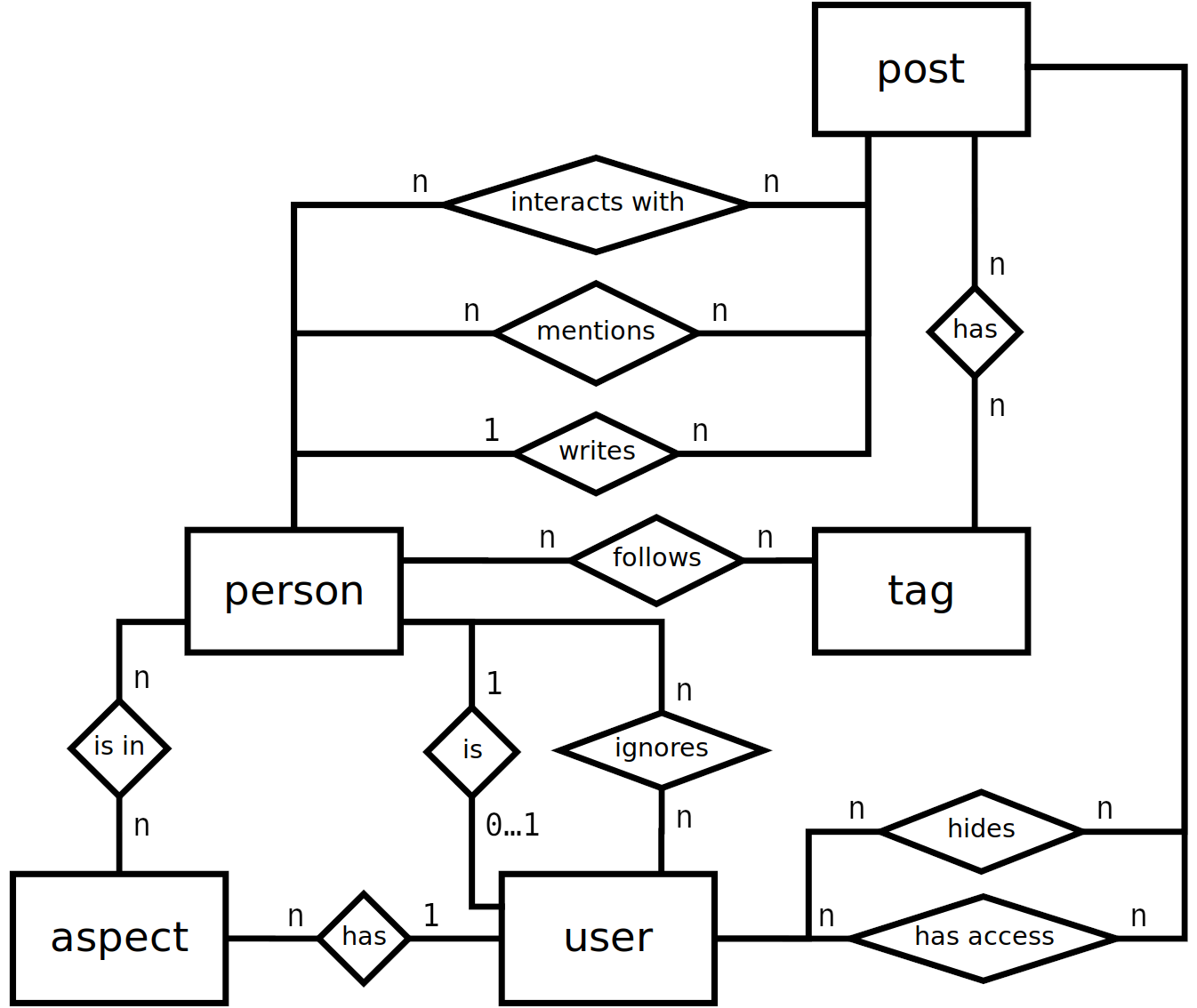
If you spot or suspect any errors, feel free to share.
In a second step, I need statistics on the average data distribution among those relations. To make sure I don’t get information I don’t want in the first place, I thought long and hard about how to go about this, especially with the diaspora* project being privacy-respecting to the core.
I need to know the total amount of data points per entity to know how much I need to insert into the tables. In addition, for every relationship in the ER model above, I need to know how “intense” they are and how this is spread.
To put this into perspective, here is an example. If I want to know how resource-heavy it is to get posts by tags, I need to know how many tags the lower 10% of posts have at maximum, the same for 50%, for 90% and the maximum tags on a post overall. This way, I can let a post generator produce random posts with appropriate probabilities for the contained tag count. However, I cannot infer private details from the posts at all, since all I have is four different markers on the probabilty of how many tags were used in a post. This is very important to me, and if you find a mistake, please tell me so.
Now posts as an entity are a bit more difficult than the others because they have multiple visibilities and their timestamp is relevant to sorting. As such, I would also need to know how many posts have been created in the last month in order to reflect and simulate recent posting behaviour. And, very importantly, I’d need to know the share of posts being public and thus implicitly visible to everyone.
I’m going to put together a few SQL commands for both MySQL and PostgreSQL and would be very happy if a few podmins would opt for sharing these numbers. If you feel you would violate the privacy of your users doing this, please talk to me so I’ll be able to revise this, as I really don’t want to have anything private in this dataset.
Edit: Updated ER model